Det här är ett avsnitt i en
webbkurs om databaser.
Skicka gärna kommentarer eller frågor
till författaren.
Översättning från ER-modellen till relationsmodellen
Det här avsnittet handlar om hur man översätter ett
ER-diagram
till
tabeller, som det går att stoppa in i en
relationsdatabashanterare.
Det kan vara bra att läsa kursavsnittet om
ER-modellering först,
och kanske också avsnittet om
relationsmodellen.
Kort kokbok
Vi börjar med en kort sammanställning om vad vi ska göra.
I de följande styckena går vi sen igenom dessa steg lite mer i detalj,
med exempel. Det är tio steg för ER-modellen, plus ett elfte steg
för att hantera den utvidgade ER-modellens arvshierarkier.
-
Varje vanlig entitetstyp blir en tabell.
Vanliga attribut blir kolumner i tabellen.
-
Varje 1:N-sambandstyp blir ett referensattribut
i "många"-entitetstypens tabell.
-
Varje 1:1-sambandstyp blir ett referensattribut i den ena
entitetstypens tabell.
-
Varje N:M-sambandstyp blir en egen tabell.
-
Varje flervägssambandstyp blir en egen tabell.
-
Attribut på sambandstyper blir kolumner.
För 1:1- och 1:N-sambandstyper i samma tabell som
den med referensattributet,
och för N:M-sambandstyper i den särskilda sambandstabellen.
-
Varje svag entitetstyp blir en tabell.
Primärnyckeln består av den svaga entitetstypens partiella nyckel,
kombinerad med den identifierande entitetstypens primärnyckel.
-
Sammansatta attribut behandlas som om de bara bestod av delarna.
-
Varje flervärt attribut blir en egen tabell.
Primärnyckeln består av entitetstypens primärnyckel,
kombinerad med det flervärda attributet.
-
Härledda attribut ignoreras.
-
Arv i EER-modellen representeras genom att varje subklass
får en egen tabell, som har samma primärnyckel som superklassen,
plus subklassens extra kolumner.
Steg 1: Vanliga entitetstyper
Jättelätt!
Varje vanlig entitetstyp blir en tabell, med samma namn som entitetstypen.
Vanliga attribut blir kolumner i tabellen.
Exempel:
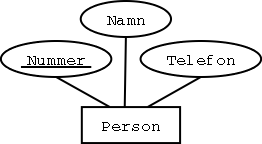
Översättning, med några inlagda exempel på hur data kan komma att se ut:
Person
| Nummer | Namn | Telefon |
|---|
| 17 | Hjalmar | 174590 |
| 4711 | Hulda | 019-94639 |
| 42 | Hjalmar | 070-7347013 |
Entitetstypens nyckel blir primärnyckel i tabellen.
Om det finns flera kandidatnycklar,
så väljer man en av dem som primärnyckel.
Välj i så fall hellre en numerisk nyckel än ett strängfält,
för tänk på att andra tabeller kanske ska ha referensattribut
till primärnyckeln i den här tabellen.
Egentligen ska det alltid finnas en nyckel angiven för varje
vanlig entitetstyp i ER-diagrammet, men om vi glömt nyckeln
(till exempel för ett samband som objektifierats)
så måste vi hitta på en nu.
Ett enkelt löpnummer i form av ett heltal brukar fungera bra.
Steg 2: 1:N-sambandstyper
Också jättelätt! Varje 1:N-sambandstyp blir ett referensattribut
i "många"-entitetstypens tabell.
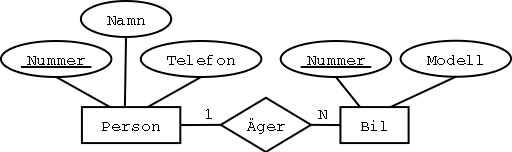
De två entitetstyperna blir förstås två tabeller.
Äger-sambandstypen blir ett referensattribut i Bil-tabellen:
Person
| Nummer | Namn | Telefon |
|---|
| 17 | Hjalmar | 174590 |
| 4711 | Hulda | 019-94639 |
| 42 | Hjalmar | 070-7347013 |
|
|
Bil
| Nummer | Modell | Ägare |
|---|
| RFN540 | Renault Scénic | 42 |
| SQL123 | Volvo 245 | 42 |
| DBA456 | Mercedes A-klass | 4711 |
| ECA911 | BMW Z3 | null |
|
BMW-bilen har ingen ägare, så det står null i kolumnen Ägare.
(Den bara står där och väntar på att någon ska hitta den!)
ER-diagrammet säger inget om att alla bilar måste ha en ägare.
Om Bil hade varit markerat som fullständigt deltagande,
alltså med ett dubbelstreck till Äger-sambandet,
så kan vi lägga på integritetsvillkoret not null när vi skapar tabellen.
Steg 3: 1:1-sambandstyper
Varje 1:1-sambandstyp blir ett referensattribut i den ena
entitetstypens tabell.
Ibland kan man slå ihop tabellerna.
Det finns alltså tre olika sätt att göra översättningen:
- Ett referensattribut i den ena tabellen
- Ett referensattribut i den andra tabellen
- Slå ihop tabellerna
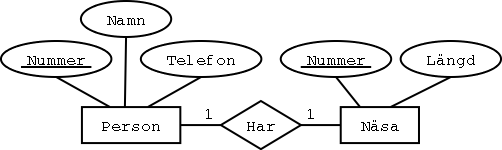
De två entitetstyperna blir förstås två tabeller.
Sen ska vi översätta Har-sambandstypen,
och vi börjar med ett första, rättframt, försök:
Person
| Nummer | Namn | Telefon | Näsa |
|---|
| 17 | Hjalmar | 174590 | 1 |
| 4711 | Hulda | 019-94639 | 2 |
| 42 | Hjalmar | 070-7347013 | null |
|
|
Näsa
| Nummer | Längd |
|---|
| 1 | 5 cm |
| 2 | 14 cm |
|
Sambandstypen Har blir attributet Näsa i Person-tabellen.
Som vi ser har den ene Hjalmar (person 17) en ganska normal näsa,
medan Hulda har en ovanligt lång näsa.
Den andre Hjalmar (person nummer 42) har ingen näsa alls. Den stackarn.
Men förmodligen (gissar vi) finns det fler personer i databasen som inte har någon näsa,
än det finns lösa näsor utan personer.
Därför är det kanske bättre att placera referensattributet i den andra tabellen.
Dels slipper vi en del null-värden, och dels känns det
(åtminstone för den som hållit på en del med databasdesign)
naturligare att näsan refererar till den person den hör till:
Person
| Nummer | Namn | Telefon |
|---|
| 17 | Hjalmar | 174590 |
| 4711 | Hulda | 019-94639 |
| 42 | Hjalmar | 070-7347013 |
|
|
Näsa
| Nummer | Längd | SitterPå |
|---|
| 1 | 5 cm | 17 |
| 2 | 14 cm | 4711 |
|
Man vill helst undvika null-värden.
Om den ena entitetstypen har fullständigt deltagande,
dvs är ansluten med ett dubbelstreck till sambandstypen,
så bör man placera referensattributet på den sidan.
I annat fall bör man välja den entitetstyp som har störst
("mest fullständigt") deltagande, i det här fallet alltså Näsa.
Ett tredje sätt är att slå ihop tabellerna.
I så fall bör bör (åtminstone nästan) alla personer ha näsor,
och (åtminstone nästan) alla näsor ha personer,
annars blir det en massa null-värden.
Person
| Nummer | Namn | Telefon | Näsnummer | Näslängd |
|---|
| 17 | Hjalmar | 174590 | 1 | 5 cm |
| 4711 | Hulda | 019-94639 | 2 | 14 cm |
| 42 | Hjalmar | 070-7347013 | null | null |
Alla tre översättningarna fungerar,
men i det här exemplet skulle jag förmodligen välja mittenalternativet,
alltså att ha ett referensattribut SitterPå i tabellen Näsa.
Steg 4: N:M-sambandstyper
Varje N:M-sambandstyp blir en egen tabell.
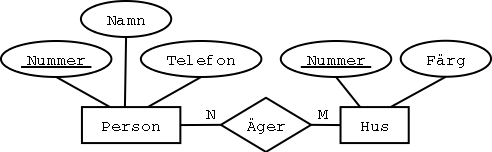
De två entitetstyperna blir förstås två tabeller.
Äger-sambandstypen blir en "mellantabell" som kopplar ihop dem:
Person
| Nummer | Namn | Telefon |
|---|
| 17 | Hjalmar | 174590 |
| 4711 | Hulda | 019-94639 |
| 42 | Hjalmar | 070-7347013 |
|
|
Äger
| Person | Hus |
|---|
| 17 | 1 |
| 17 | 2 |
| 17 | 3 |
| 4711 | 3 |
|
|
Hus
| Nummer | Färg |
|---|
| 1 | Rött med vita knutar |
| 2 | Rött med vita knutar |
| 3 | Rött med vita knutar |
| 4 | Chockpistage |
|
Tabellen Äger har en primärnyckel som består av
både Person och Hus.
Dessutom är Person referensattribut till tabellen Person,
och Hus är referensattribut till tabellen Hus.
Person 42 äger inget hus, och hus 4 har ingen ägare.
Hus 3 ägs gemensamt av två personer.
Tekniken med en mellantabell kan användas också när man översätter 1:1-samband
och 1:N-samband.
Det kan vara bra till exempel om deltagandet är väldigt lågt på båda sidor
om sambandstypen, så att det skulle blir många null-värden med de vanliga lösningarna.
För 1:1- och 1:N-samband blir primärnyckeln i mellantabellen inte
sammansatt av primärnycklarna från båda de hopkopplade tabellerna.
Steg 5: Sambandstyper av högre grad än två
Trevägssamband, och samband av ännu högre grad,
är det enklast att göra en mellantabell av.
För ett många-till-många-till-många-samband så måste man ha mellantabellen,
men ibland, till exempel för 1:1:1-samband, kan man klara sig utan en extra tabell.
Precis när man kan, och inte kan, klara sig utan tabell lämnas som övning
åt läsaren.
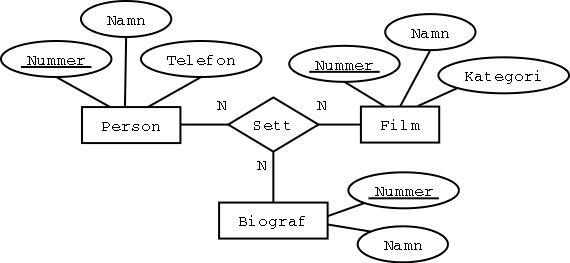
Översätt alltså sambandstypen Sett med en egen tabell,
som har en sammansatt primärnyckel bestående av primärnycklarna
från de tre hopkopplade tabellerna:
Sett
| Person | Film | Biograf |
|---|
| 17 | 1 | 1 |
| 17 | 1 | 2 |
| 17 | 2 | 1 |
| 42 | 2 | 2 |
Person
| Nummer | Namn | Telefon |
|---|
| 17 | Hjalmar | 174590 |
| 4711 | Hulda | 019-94639 |
| 42 | Hjalmar | 070-7347013 |
|
|
Film
| Nummer | Namn | Kategori |
|---|
| 1 | Spindelmannen | Superhjältar |
| 2 | Titanic | Romantik |
| 3 | Exit wounds | Åtgärdsfilm |
|
|
Biograf
| Nummer | Färg |
|---|
| 1 | Rigoletto |
| 2 | Filmstaden |
| 3 | Röda kvarn |
|
Steg 6: Attribut på sambandstyper
Attribut på sambandstyper blir kolumner.
För 1:1- och 1:N-sambandstyper i samma tabell som
den med referensattributet,
och för N:M-sambandstyper i den särskilda sambandstabellen.
Samma exempel på 1:N-samband som förut, men med ett attribut på sambandet:
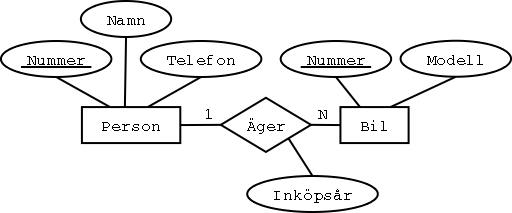
Vi översätter precis som vi gjorde förut,
men lägger till kolumnen Inköpsår bredvid referensattributet Ägare:
Person
| Nummer | Namn | Telefon |
|---|
| 17 | Hjalmar | 174590 |
| 4711 | Hulda | 019-94639 |
| 42 | Hjalmar | 070-7347013 |
|
|
Bil
| Nummer | Modell | Ägare | Inköpsår |
|---|
| RFN540 | Renault Scénic | 42 | 2000 |
| SQL123 | Volvo 245 | 42 | 1981 |
| DBA456 | Mercedes A-klass | 4711 | 2002 |
| ECA911 | BMW Z3 | null | null |
|
Samma exempel på N:M-samband som förut, men med ett attribut på sambandet:
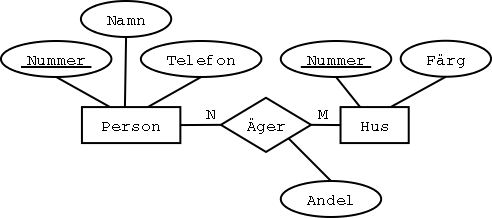
Vi översätter precis som vi gjorde förut,
men lägger till kolumnen Andel i tabellen Äger:
Person
| Nummer | Namn | Telefon |
|---|
| 17 | Hjalmar | 174590 |
| 4711 | Hulda | 019-94639 |
| 42 | Hjalmar | 070-7347013 |
|
|
Äger
| Person | Hus | Andel |
|---|
| 17 | 1 | 100% |
| 17 | 2 | 100% |
| 17 | 3 | 30% |
| 4711 | 3 | 70% |
|
|
Hus
| Nummer | Färg |
|---|
| 1 | Rött med vita knutar |
| 2 | Rött med vita knutar |
| 3 | Rött med vita knutar |
| 4 | Chockpistage |
|
Steg 7: Svaga entitetstyper
Varje svag entitetstyp blir en tabell.
Primärnyckeln består av den svaga entitetstypens partiella nyckel,
kombinerad med den identifierande entitetstypens primärnyckel.
Exempel:
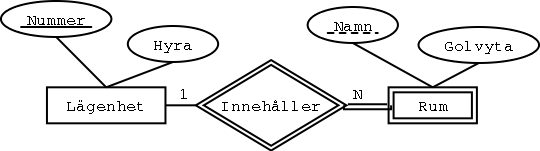
Lägenhet
| Nummer | Hyra |
|---|
| 1 | 4500 |
| 2 | 2500 |
|
|
Rum
| Lägenhet | Namn | Golvyta |
|---|
| 1 | kök | 14 |
| 1 | badrum | 5 |
| 1 | sovrum | 20 |
| 1 | vardagsrum | 20 |
| 2 | kök | 8 |
| 2 | badrum | 3 |
| 2 | sovrum | 12 |
|
Tabellen Rum har en primärnyckel som består av
både Lägenhet och Namn.
Dessutom är Lägenhet referensattribut till tabellen Lägenhet.
Steg 8: Sammansatta attribut
Sammansatta attribut behandlas som om de bara bestod av delarna.
Exempel:
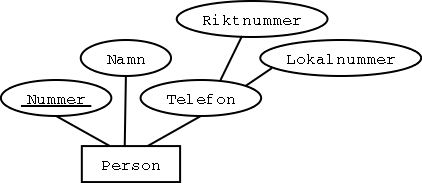
Person
| Nummer | Namn | Riktnummer | Lokalnummer |
|---|
| 17 | Hjalmar | null | 174590 |
| 4711 | Hulda | 019 | 94639 |
| 42 | Hjalmar | 070 | 7347013 |
Steg 9: Flervärda attribut
Varje flervärt attribut blir en egen tabell.
Primärnyckeln består av entitetstypens primärnyckel,
kombinerad med det flervärda attributet.
Exempel:
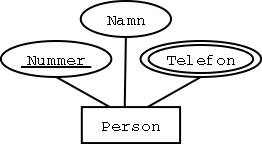
Person
| Nummer | Namn |
|---|
| 17 | Hjalmar |
| 4711 | Hulda |
| 42 | Hjalmar |
|
|
Telefonnummer
| Person | Telefonnummer |
|---|
| 17 | 174590 |
| 17 | 260088 |
| 42 | 070-7347013 |
| 42 | 174590 |
| 4711 | 019-94639 |
|
Steg 10: Härledda attribut
Härledda attribut ignoreras.
Behövs det verkligen ett exempel på hur man struntar i ett attribut?
Men okej då:

Person
| Nummer | Namn | BorI |
|---|
| 17 | Hjalmar | 1 |
| 4711 | Hulda | 1 |
| 42 | Hjalmar | 3 |
|
|
Hus
|
Notera att jag snikade in ett exempel på ett N:1-samband här.
Förut har vi bara sett 1:N-samband, men ett N:1-samband hanteras precis likadant,
fast förstås spegelvänt.
Dessutom ser vi att man kan ha en tabell som bara består av en enda kolumn.
Det är inget konstigt med det.
Steg 11: Arv i EER-modellen
Arv i EER-modellen kan översättas till tabeller på flera olika sätt,
men det som nästan alltid är bäst är att varje subklass
får en egen tabell, som har samma primärnyckel som superklassen,
plus subklassens extra kolumner. En entitetsinstans har en rad
i alla tabellerna för de entitetstyper som den instansen tillhör.
Ett exempel med personer, som (förutom att de är personer)
också kan vara studenter och lärare:
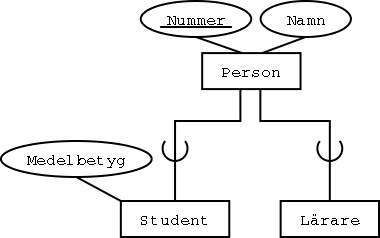
Varje entitetstyp blir en tabell:
Person
| Nummer | Namn |
|---|
| 17 | Hjalmar |
| 4711 | Hulda |
| 42 | Hjalmar |
| 4712 | Bengt |
|
|
Student
| Nummer | Medelbetyg |
|---|
| 17 | 3.9 |
| 4711 | 3.2 |
|
|
Lärare
|
Förklaring:
-
Alla personer finns med i tabellen Person.
Den tabellen påverkas inte av arvet,
utan ser ut precis som den skulle göra om subklasserna inte fanns.
-
Tabellen Student innehåller alla de personer som är studenter.
Primärnyckeln Nummer är samma som primärnyckeln i Person,
och den är dessutom ett referensattribut till Person.
-
Tabellen Lärare innehåller alla de personer som är lärare.
Primärnyckeln Nummer är samma som primärnyckeln i Person,
och den är dessutom ett referensattribut till Person.
En lärare har inga egna attribut, så hela idén med tabellen Lärare
är att visa vilka av personerna från tabellen Person som är lärare.
Den förste Hjalmar (person 17) är student.
Nykomlingen Bengt är lärare.
Hulda är både student och lärare.
Den andre Hjalmar (person 42)
är varken lärare eller student, utan bara en person.
För att få fram all information om en viss entitetsinstans,
till exempel Hulda, måste man alltså titta i flera olika tabeller.
Sambandstyper ärvs också, och de hanteras på samma sätt som attribut.
Anta att personer kan bo i hus, och studenter kan läsa program:
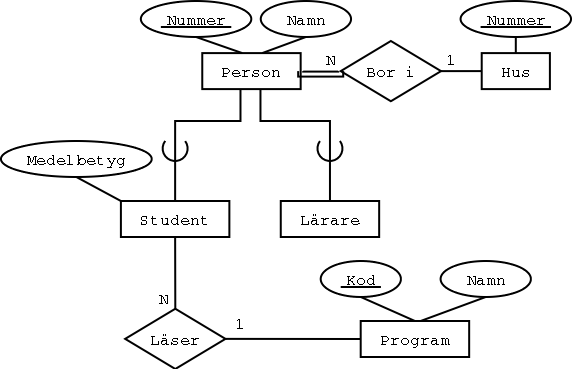
När vi översätter till tabeller så bli sambandet Bor i
ett referensattribut i tabellen Person,
och sambandet Läser
ett referensattribut i tabellen Student:
Person
| Nummer | Namn | BorI |
|---|
| 17 | Hjalmar | 1 |
| 4711 | Hulda | 1 |
| 42 | Hjalmar | 3 |
| 4712 | Bengt | 1 |
|
|
Student
| Nummer | Medelbetyg | Läser |
|---|
| 17 | 3.9 | A |
| 4711 | 3.2 | C |
|
|
Lärare
|
Hus
|
|
Program
| Kod | Namn |
|---|
| A | Arkitektprogrammet |
| B | Bagarprogrammet |
| C | Datavetenskapliga programmet |
|
Vi ser till exempel att Hulda bor i hus nummer 1,
och att hon läser Datavetenskapliga programmet.
Litteratur
Av Thomas Padron-McCarthy
(e-post: tpm@ida.liu.se).
Copyright,
alla rättigheter reserverade, osv.
Senaste ändring:
9 juli 2002